Every parcel you’ve ever received traveled most of its distance cheaply. A container ship crosses an ocean for cents per kilogram. A truck runs a highway lane at near-perfect utilization. Then the parcel reaches a depot twenty minutes from your door, and the economics fall off a cliff.
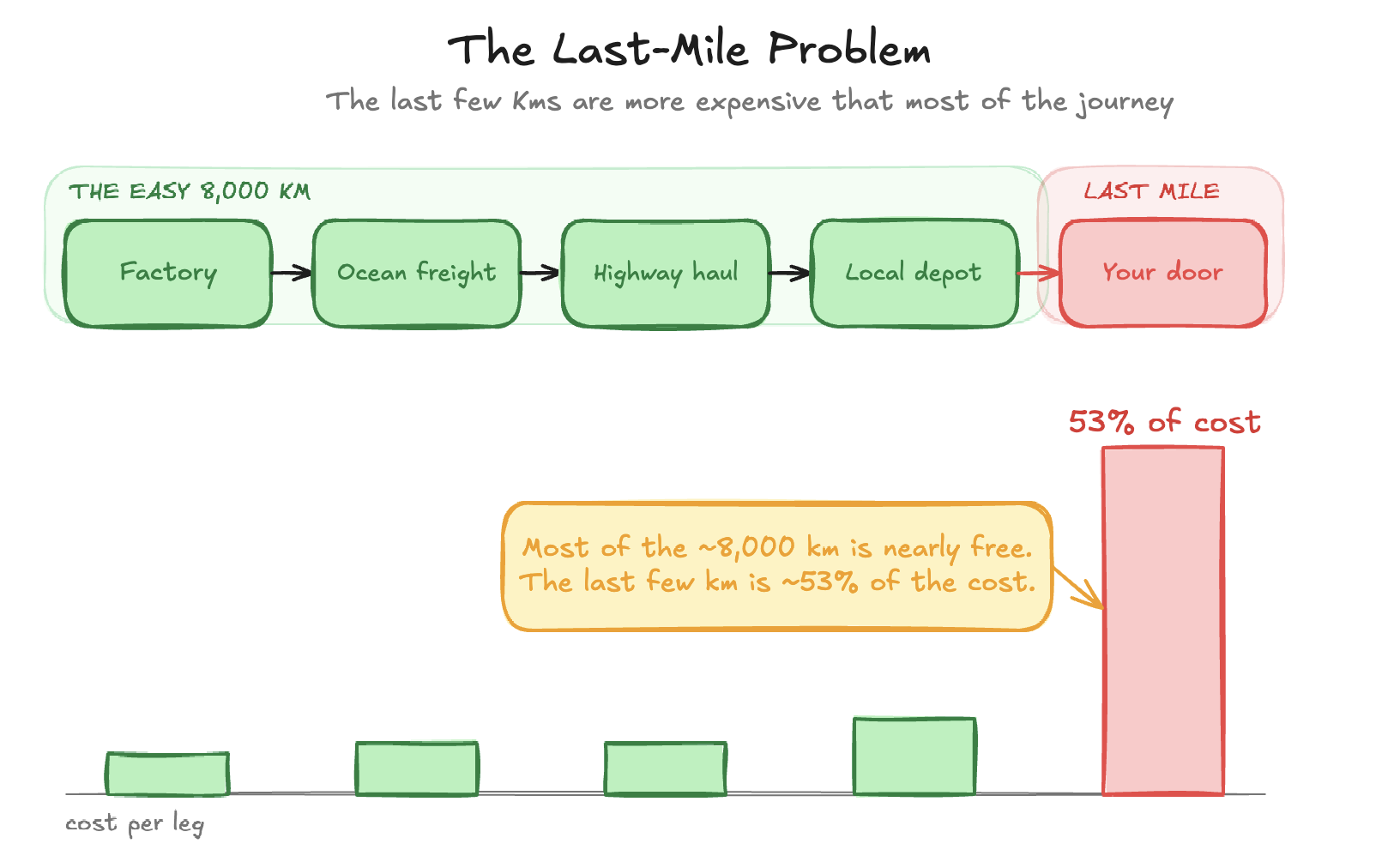 Figure 0: The Last Mile Delivery Problem
Figure 0: The Last Mile Delivery Problem
The numbers say it plainly. Last-mile delivery now absorbs roughly 53% of total shipping cost — up from 41% in 2018, and now the single largest line item in the fulfillment chain, having quietly overtaken warehousing and middle-mile freight combined [1][2].
Around 5% of deliveries fail on the first attempt; each failure costs about $17 in redelivery, labor, and support; and up to 45% of those failures trace back to a bad address [2][3].
Labor alone is 50–60% of last-mile cost, and out-of-route miles eat another ~10% of total mileage before anyone optimizes anything [3].
Numbers tell the story themselves. This isn’t just a rounding error, it’s where time and money goes.
I find this interesting for a reason that has little to do with logistics. The last mile is expensive because it refuses to generalize. (Deep Learning people: Rings a bell?)
The ocean crossing is one problem. The last mile is a million tiny problems: this street, this building, this gate code, this customer who works nights and the messiness is irreducible.
So this is a case study told as a then / now comparison across the deep-learning era and the agentic one. The logistics are real. The lesson is about how you design and deploy systems.
Two regimes, not one
The first mistake is treating “last mile” as one system. It is two, with completely different latency, consistency, and failure characteristics. an Conflating them is an architectural decision mistake.
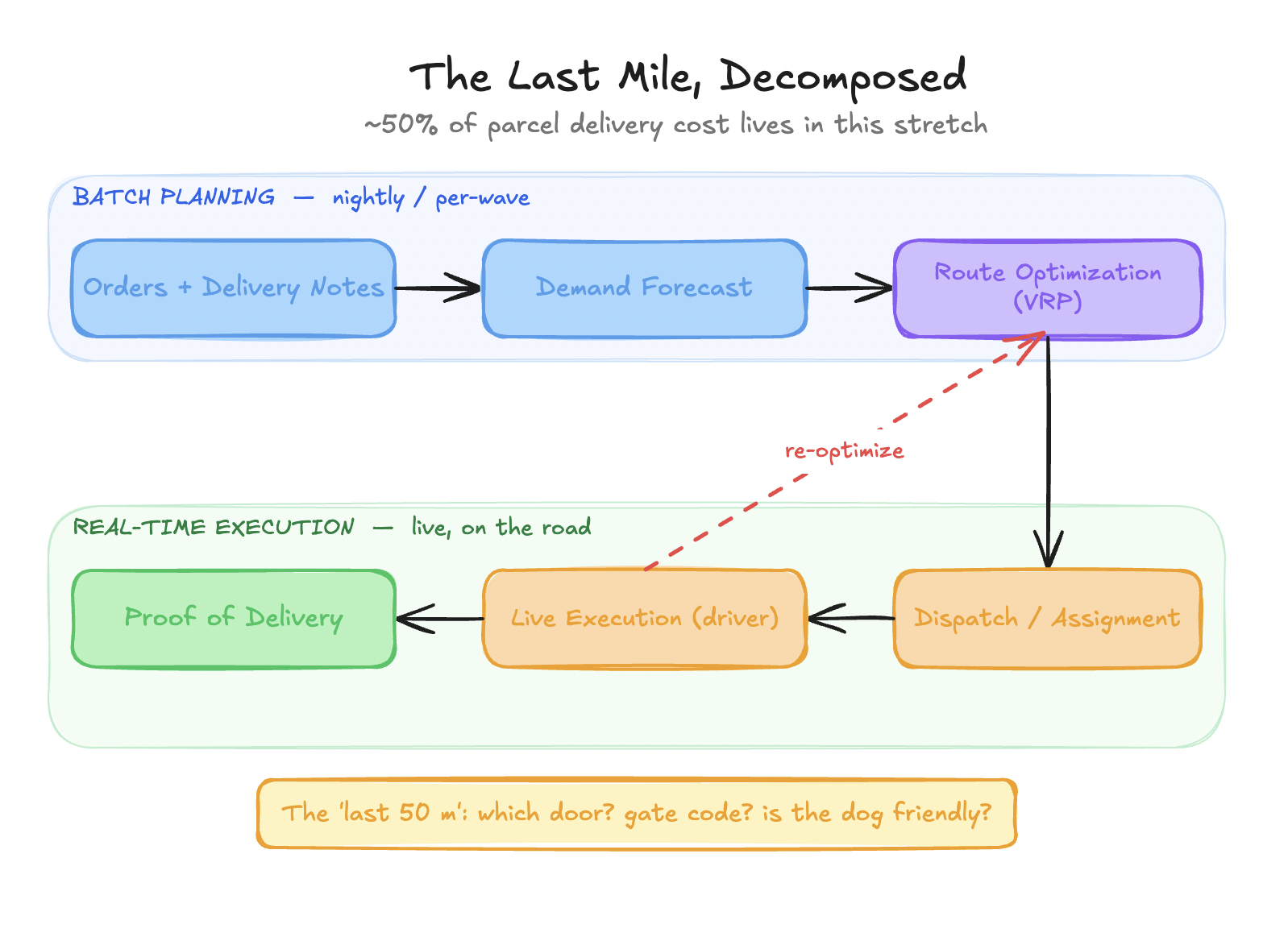
Figure 1 — Planning is a batch problem; execution is a real-time one. They have different SLAs, different failure modes, and want different machinery. Separating them is the first design call.
Batch planning: Intelligence means Planning
Batch planning runs nightly or per-wave. You know tomorrow’s orders, you have minutes of compute, and you want provably good routes. This is where the heavy machinery lives: demand forecasting and the Vehicle Routing Problem (VRP) — the NP-hard combinatorial core, in all its variants (capacity, time windows, pickup-and-delivery).
The canonical industrial proof point here is UPS’s ORION. It evaluates more than 200,000 alternative routes for a single driver’s day and runs on the order of 30,000 route calculations a minute across 55,000+ U.S. drivers [4]. The payoff is comically large for a problem that sounds dull: roughly 100 million miles and 10 million gallons of fuel saved per year, and $300–400 million in annual cost avoidance [4][5].
💡 UPS’s own rule of thumb: Shaving just one mile per driver per day is worth about $50 million each year [5].
That single number is the last mile: trivial per-stop margins, enormous aggregate stakes.
Real-time execution: Intelligence means Action
This is a different animal. A driver is on the road, a delivery just failed, traffic happened, a customer rescheduled. You have seconds, not minutes, and the world is actively invalidating your earlier plan. This is the regime that generates most of the cost and where the last fifty meters lives: which door, which gate, the code is 1234#, ring twice, the dog is friendly. Unstructured, per-address, rarely in the training set and the direct cause of those expensive failed deliveries.
Here’s the part a systems designer should actually take from ORION, and it isn’t the algorithm. UPS spent around $250 million and roughly three years of field testing before full rollout, and — in their own framing — had to blend century-old delivery practice with modern optimization, against drivers who initially didn’t trust the routes [4]. The math was solved in a lab. The deployment took years. Hold that thought; it’s the whole essay.
Then: a model for every box (~2018–2022)
If you’d handed me this in 2020, in all fairness amidst COVID-19 and my Masters assignments, I wouldn’t have listened to you.
Jokes apart,I’d have thought of if differently in the pre-LLM era. Each sub-problem became its own trained artifact.
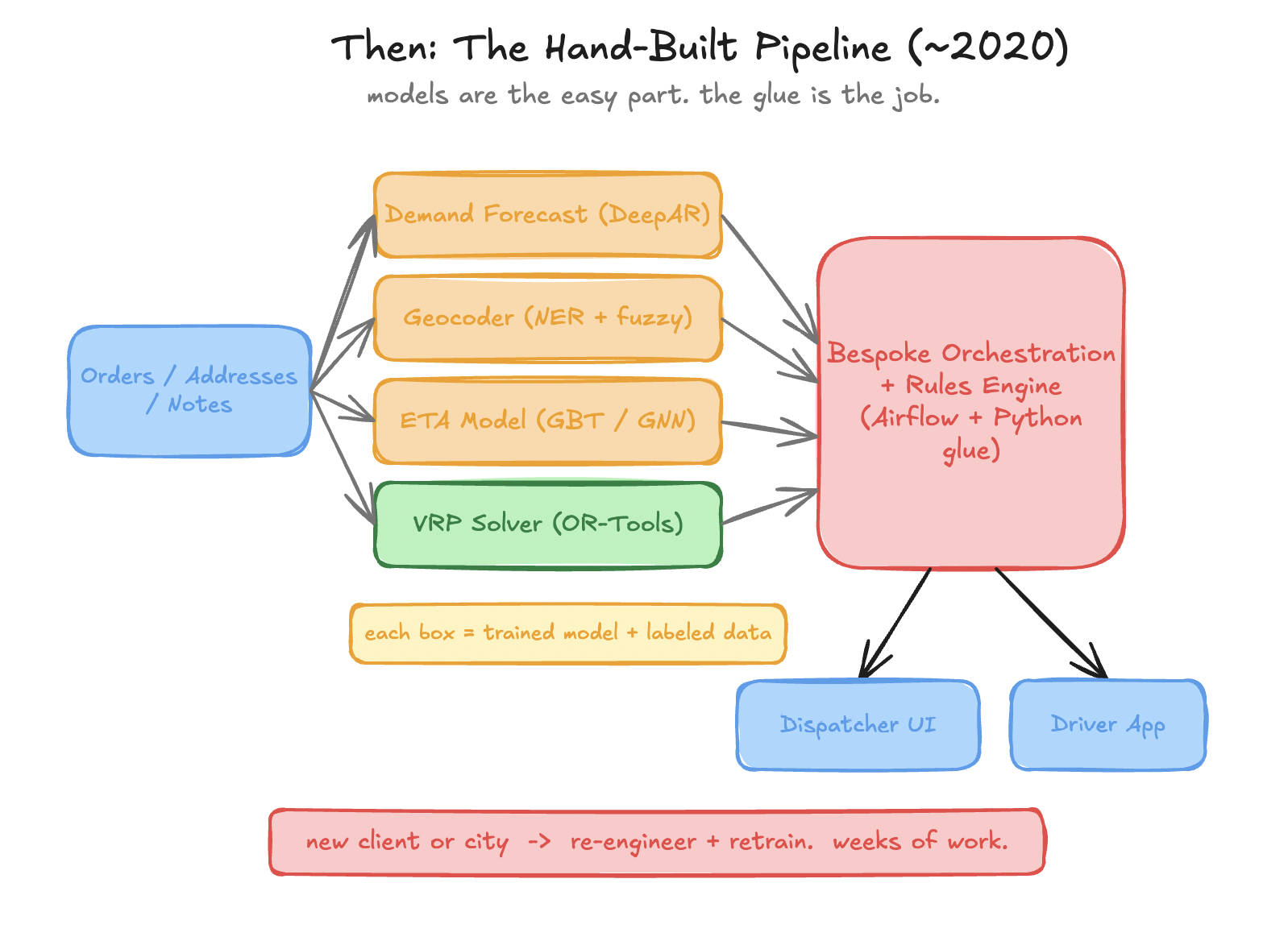
Figure 2: Every capability is a separate trained model, wired together by hand, syntactic sugar and Magic. Developing the models was just a small part of the job. The red block is the job.
DeepAR or gradient-boosted trees for the forecast. OR-Tools or Gurobi for the VRP. Gradient-boosted trees + then graph neural nets for ETA. The benchmark for ETA in this era is the DeepMind × Google Maps GNN, which modeled the road network as a graph of “supersegments” and cut real-time ETA error by up to 50% in cities like Berlin, Tokyo, and Sydney (Derrow-Pinion et al., 2021) [6]. For addresses: an NER(Named Entity Recognition) pipeline plus fuzzy matching plus a geocoding API. Four clean boxes, four clean papers.
Here is what the architecture diagrams of that era always understated: none of those models were the hard part. The hard part was the red block in the middle — the orchestration. The Airflow DAGs, the rules engine, the exception handlers, the data validation, the dispatcher tooling. It was 80% of the work and 100% bespoke. Every model assumed clean inputs; reality supplied dirty ones; the glue absorbed the difference, and it did not generalize across so much as a single street.
It worked — companies ran billions of parcels on architectures shaped exactly like this. But it carried a tax, and the tax has a name.
The tax is distribution shift
This is my actual hobbyhorse, so indulge me for a paragraph.
Every model in that pipeline was trained on a distribution: this city’s addresses, this depot’s service times, this fleet’s behavior. Move to a new city and the addresses geocode differently, the traffic patterns invert, the service-time priors are wrong, the customer notes are in another language. The model didn’t break. The world moved out from under it. (For ML people, here’s our arch nemesis: Out of Distribution (OOD) data.)
So every new client, every new city, was a re-engineering project. Re-collect labels. Re-train. Re-tune the rules engine for local edge cases. Weeks to months before a single optimized route came out the other end. The model was generic; the deployment was bespoke; and the bespoke part is where the calendar went. If you’ve ever wondered why “we have a great model” and “we shipped to the customer” are two quarters apart, this is the reason.
💡 The agentic version does not make that tax disappear. It makes it dramatically cheaper to pay.
Now: the agent is the glue (2023 →)
Here is the version I’d build today. I want to lead with the thing it does not do, because that’s where most people get this wrong.
It does not solve the VRP. A routing problem with five hundred stops is NP-hard, and OR-Tools or Gurobi will return a near-optimal tour in seconds using decades of combinatorial-optimization research. An LLM asked to do the same produces a confident, plausible, wrong answer.
This isn’t just me dumping my opinion. It’s the explicit design principle from some of the most credible published system in this space. Microsoft Research’s OptiGuide, used in production for Azure’s cloud supply chain, is built (in the authors’ words)
💡 “not to replace optimization technology by LLMs, but rather use optimization solvers in tandem” [7].
The LLM translates a plain-language query into solver inputs; the classical solver runs under the hood; the LLM turns the result back into something a planner can act on. It’s reported at over 90% accuracy on real what-if queries in Azure practice, with a safeguard layer that validates generated code before it ever reaches the solver [7][8].
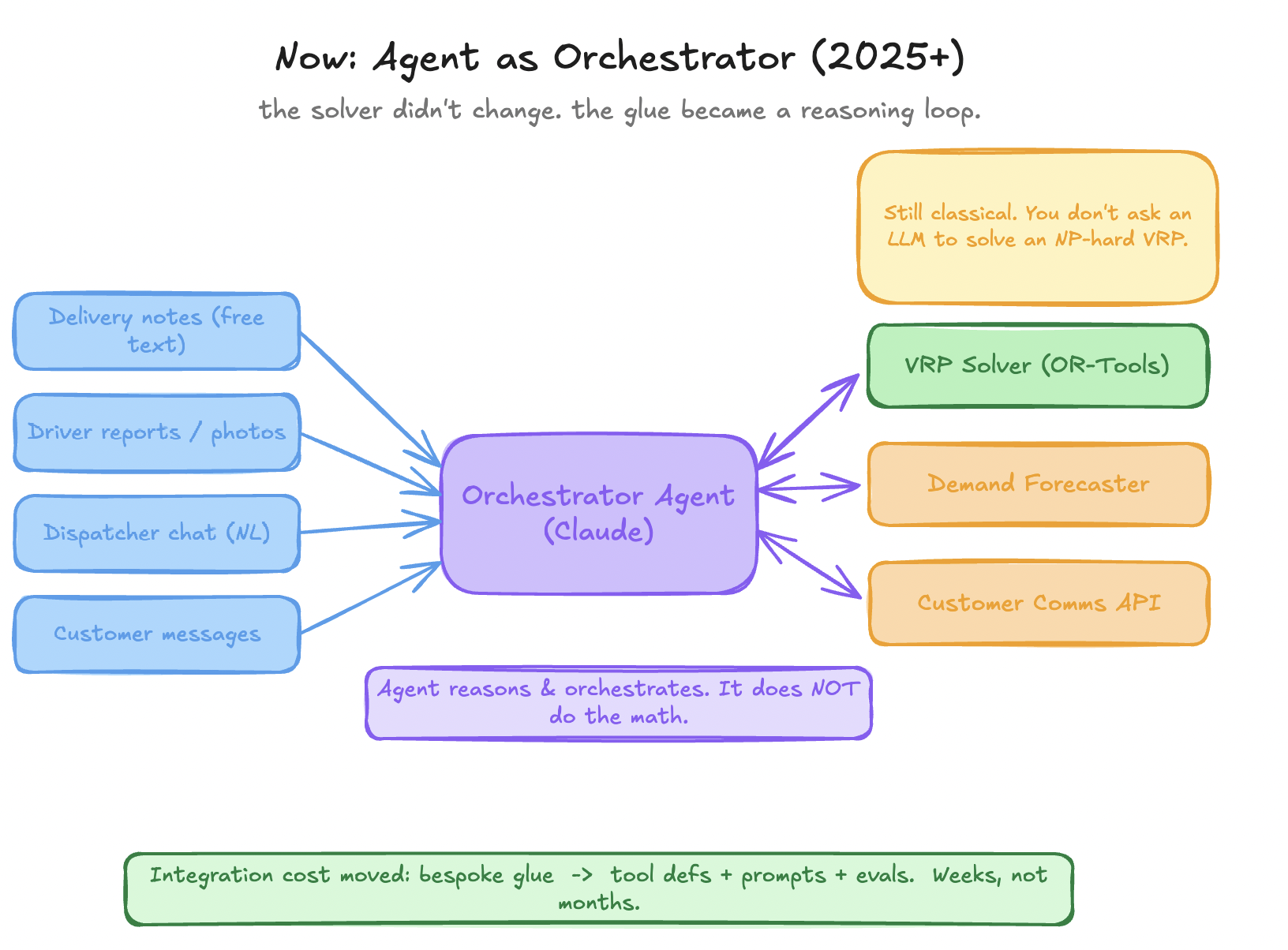
Figure 3 — The solver is unchanged (still green). What collapses is the red orchestration block. Reason at the edges, optimize in the middle, guard the boundary.
That architecture — reason at the edges, optimize in the middle, guard the boundary — is the whole game. Three things change as a result.
Unstructured input stops needing its own model. “Leave at the back gate, code 1234, the dog is friendly” used to require an NER pipeline and a pile of regexes that broke on the next city’s phrasing. Now it’s a sentence the agent reads and turns into structured constraints for the solver. An entire subsystem collapses into a tool call and a prompt.
Exceptions become reasoning instead of pre-written rules. Driver 7 calls in sick at 6am; half their route is suddenly unassigned. In the old world that’s a code path someone had to anticipate and maintain. In the new one the agent reasons through it: pull driver 7’s stops, re-invoke the solver with updated vehicle availability, notify affected customers, and flag the three time-window deliveries that genuinely can’t be saved for a human. The long tail of “stuff the pipeline never anticipated” is exactly what an agent is good at or atleast improving every year. The current OR literature frames this division of labor directly as human–LLM–solver complementarity rather than substitution [9].
The dispatcher gets a natural-language interface to the optimizer. “Re-route everything north of the river, we lost a van” becomes a constraint change the agent translates and the solver executes. The human stays in the loop where judgment matters, without learning the solver’s API.
The payoff is the green bar at the bottom of Figure 3. The integration cost didn’t vanish — it moved. Bespoke glue became tool definitions, prompts, and evals. The thing that took months now takes weeks.
And this shift is one of the reasons why have we seen a rise in the role of Forward Deployed Engineers in the last year. What reqruies multiple domain experts from is now expected from an Engineer+LLM duo.
The discipline: where the LLM must not go
If something is too good to be true, it most likely is.
Surveys of multi-agent optimization frameworks warn that the flexibility comes with “substantial computational overhead” and an “increased risk of cascading errors,” and that these systems are rarely benchmarked against simpler baselines [10]. Based on that if I’ve to translate that to a depot running on SLAs, I’d say:
Keep the model out of the inner loop. The agent plans and re-plans a handful of times per wave. It does not sit inside the solver’s iteration running millions of times. Latency and cost both forbid it and “computational overhead” is precisely the failure mode the surveys name.
Never let it do arithmetic a tool should do. If a number matters like a distance, a capacity, an ETA, it comes from a deterministic service, not from token prediction. The agent’s job is to choose which tool with what inputs, not to be the tool. That boundary is exactly OptiGuide’s
safeguard.Logistics runs on SLAs, and SLAs want determinism and auditability. “Why did parcel X get routed that way” needs a reproducible answer. “Cascading errors” in an audit trail are how you lose a contract. Decisions are logged, evaluated, and constrained — you build the eval harness before you grant the autonomy.
Cost control is a first-class design constraint. An agent invoked a few times per planning wave is fine. An agent invoked per-stop, per-parcel, quietly bankrupts the unit economics while looking great in the demo. (For people who’ve been in Computer Scienc domain, might wanna remember, Economic Denial of Sustainabiltiy was a real thing after DDoS era.)
None of this is an argument against deploying. It’s the difference between a demo and a system. The demo is one good route on a clean dataset. The system survives the depot where the addresses are wrong, the driver who went off-script, and the finance team asking why the inference bill tripled.
My 2 Cents or Last Mile’s 200 Meters (whichever is cheaper)
Last-mile delivery is hard because the value lives in the final, context-specific stretch that doesn’t generalize. The specific door, the specific exception, the specific city. Last-mile deployment is hard for precisely the same reason. A frontier model is the ocean crossing: solved once, available to everyone, cheap per token. Getting it to work inside one company’s messy, specific, real operation is the last mile and that’s where most of the cost, the failure, and the value sit.
The pre-agentic era paid that deployment tax in re-engineering. The agentic era pays it in context design, tool boundaries, and evals and it’s an order of magnitude cheaper to move, which is exactly why the work is now worth embedding an engineer to do.
The model was never the bottleneck. The last mile was. It still is.
P.S: If you’ve any feedback, please do share it with me. This wasn’t a field I’m truly an expert in, so there might be some mistakes.I’d be happy to receive your critiques, corrections and suggestions via email or LinkedIn.
References
- Cascadia / Statista — Share of last-mile delivery costs out of total shipping costs, 2018 vs 2023 (41% → 53%). https://www.statista.com/statistics/1434298/last-mile-share-of-total-shipping-costs/
- GoBolt — Last Mile Delivery Problems: Causes, Costs & Solutions (53% cost share; failed-delivery cost; ~45% of failures from address errors). https://www.gobolt.com/blog/last-mile-delivery-problems/
- Elite EXTRA — Last Mile Delivery Costs: The Most Expensive Step in the Supply Chain (labor 50–60%; ~$17.78 per failed delivery; ~5% failure rate). https://eliteextra.com/last-mile-delivery-costs-the-most-expensive-step-in-the-supply-chain/
- INFORMS — UPS On-Road Integrated Optimization and Navigation (ORION) O.R. success story (200,000+ route options per route; ~$250M build cost; $300–400M/yr; 10M gal fuel). https://www.informs.org/Impact/O.R.-Analytics-Success-Stories/UPS
- BSR — Looking Under the Hood: ORION Technology Adoption at UPS (six-to-eight miles/route/day; “$50M/yr per mile” rule of thumb). https://www.bsr.org/en/case-studies/center-for-technology-and-sustainability-orion-technology-ups
- Google DeepMind — Traffic prediction with advanced Graph Neural Networks (up to 50% ETA-error reduction; Derrow-Pinion et al., CIKM 2021). https://deepmind.google/discover/blog/traffic-prediction-with-advanced-graph-neural-networks/
- Li, Mellou, Zhang, Pathuri, Menache et al. (Microsoft Research) — Large Language Models for Supply Chain Optimization (OptiGuide), arXiv:2307.03875. https://arxiv.org/abs/2307.03875
- Microsoft Research — OptiGuide: GenAI for Supply Chain Optimization (in-production Azure what-if queries; >90% accuracy as summarized in OR surveys). https://www.microsoft.com/en-us/research/project/optiguide-genai-for-supply-chain-optimization/
- Agentic LLMs in the supply chain: towards autonomous multi-agent consensus-seeking, International Journal of Production Research (2025) — orchestration patterns; human–LLM–solver complementarity. https://www.tandfonline.com/doi/full/10.1080/00207543.2025.2604311
- ORThought: Benchmarking and Automating Logistics Optimization Modeling via Structured LLM Reasoning, arXiv:2508.14410 (2026) — multi-agent overhead and cascading-error risks; scarcity of simple-baseline comparisons. https://arxiv.org/html/2508.14410